The model raises near- to medium-term disruption risks for IT services with the caveat that model capabilities are largely unproven in real-world scenarios due to a lack of a public release.

FinTech BizNews Service
Mumbai, April 11, 2026: The latest Kotak Institutional Equities report on IT Services provide useful analysis for IT Services Firms.
Mythos raises AI disruption risks for IT services firms
Anthropic’s Mythos model exhibits a step-jump in benchmark performance across software engineering tasks, a deviation from the trajectory of incremental/moderate improvements in the recent past. Mythos provides a large improvement in agentic software development, based on qualitative assessments. We believe that the model raises near- to medium-term disruption risks for IT services with the caveat that model capabilities are largely unproven in real-world scenarios due to a lack of a public release. Risks can be higher for firms with more exposure to application services.
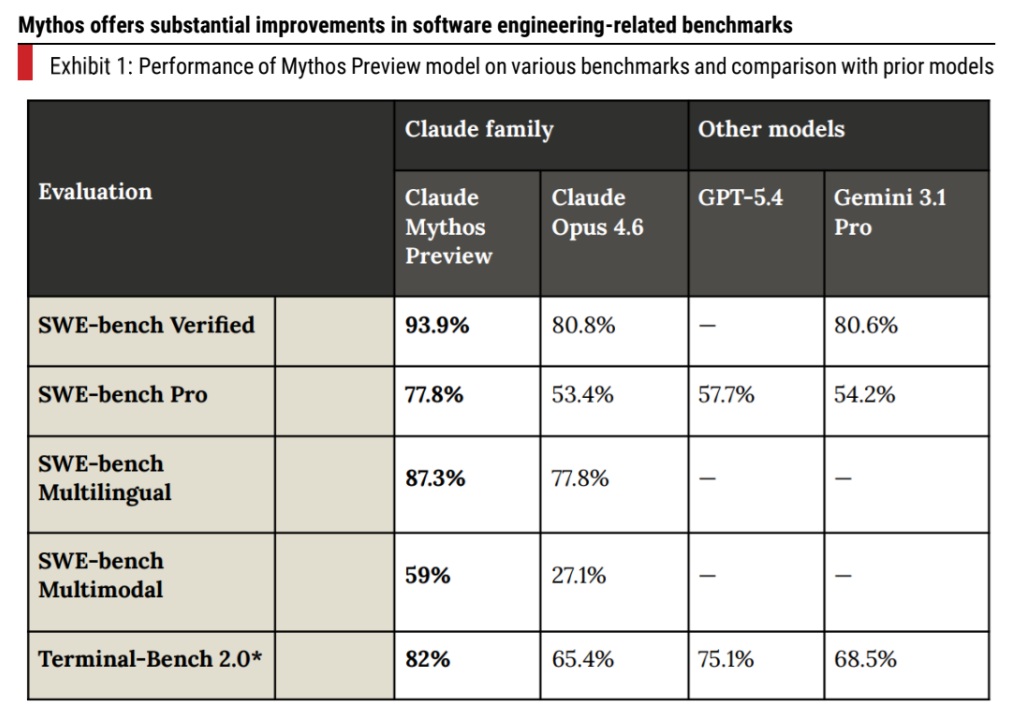
Step-jump in benchmark performance across software engineering tasks
The benchmark performance of Claude Mythos Preview across software development-related and other tasks, as per its system card. The performance improvements are substantial on a high base in many cases (compared with the previous Opus 4.6 model). A few instances: Opus 4.6 showcased an ~6% and ~0% improvement in Terminal Bench 2.0 and SWE bench-verified benchmarks over Opus 4.5. Mythos demonstrates 17 percentage points and 13 percentage points improvement in respective benchmarks compared to Opus 4.6. According to Anthropic, the model is also significantly better in other aspects, such as lower hallucination rates, better alignment to user intentions and instructions, and long context recall, which can drive higher adoption in IT services tasks. Anthropic also notes large improvements in agentic coding based on user feedback.
Raises disruption risks for IT services in near-to-medium term
Mythos’ significant improvement in software engineering-related tasks is a departure from the trend of incremental improvements between consecutive frontier models. These developments could have implications for IT services firms, in our view. The realization of similar improvements in real-world scenarios risks turning our estimate of 3-3.5% annual growth headwind for the industry for the next three years from prudent to practical. Further downside risks could also increase, especially if large capability improvements continue in future frontier models.
Further compounds near-term deflation risks for services, especially in apps
The Mythos model provides a firmer foundation for AI disruption-related concerns and could pressurize the valuation multiples of IT services companies. We expect Mythos to increase efficiencies across all IT services segments. Yet, stronger agentic software engineering capabilities could result in widening the gap in productivity increase between application services (also called custom application development) and other IT services segments (including BPO). Among Tier 1 Indian IT, Infosys has a higher exposure to apps, while HCLT has a lower exposure. In general, mid-tier IT has a higher exposure to apps, with Persistent leading the pack among the Indian names. Mid-tier challengers can offset headwinds by share gains from slower to adapt incumbents.
Expect acceleration of AI-driven opportunities in services
We expect an acceleration of opportunities, such as the modernization of legacy systems and data foundations, which will partially offset the revenue deflation impact. Enterprises might opt for higher custom application development as well. This can provide further offset. We expect the Mythos model—once released to the public—to accelerate GenAI-driven business use cases, providing large new opportunities to Indian IT and plugging the deflation impact arising from the adoption in services.
Provides large improvement in agentic software development based on qualitative assessments
Anthropic has provided qualitative assessments of Mythos Preview’s behavior in software engineering contexts in pages 201-203 of the system card. Anthropic notes that generally users have found Mythos Preview to be a large improvement in both capabilities and behavior for agentic coding, especially when used in autonomous settings. This has the potential to enhance the scope of agentic coding in software development to get a significant productivity increase even in brownfield and complex greenfield environments, in our view.
We provide the below key excerpts (in italic) from the system card that provide interesting insights regarding Mythos’ software engineering capabilities relative to prior models.
4 | Better agentic software development capabilities. A core behavioral shift we found is that Mythos Preview can be handed an engineering objective and left to work through the whole cycle: investigation, implementation, testing and reporting results. In long agentic sessions, it stays on task, fires off subagents to parallelize research and chooses to return to the human while waiting for background work to complete rather than stopping. |
4 | More autonomy in tasks. Early testers described being able to “set and forget” on many-hour tasks for the first time…. Interacting with the model requires less steering and is more autonomous: “describe the task spec and how to verify progress, and come back later.” |
4 | Works better in agentic coding rather than as an AI assistant. Importantly, we found that when used in an interactive, synchronous, “hands-on-keyboard” pattern, the benefits of the model were less clear. When used in this fashion, some users perceived Mythos Preview as too slow and did not realize as much value. The autonomous, long-running agent harnesses better elicited the model’s coding capabilities. |
4 | Large improvements in code reviews. In code review, Mythos Preview works more like a senior engineer. It tends to catch even extremely subtle bugs and to identify root causes and why bugs exist rather than just symptoms. Testers have watched it catch issues that other capable models passed over and then diagnose and repair the problem rather than simply flagging it. The easy catches that dominate the human review of model-generated code are much less common. |
4 | Higher ability to self-correct. Self-correction is sharper than in earlier Claude models and more specific. For instance, when one of its own subagents returned incorrect information, Mythos Preview noticed, diagnosed why the subagent had made a mistake, and fixed the underlying issue rather than simply retrying. Testers with extensive experience of earlier models called this the first time they had seen follow-through on a pattern the prior version would acknowledge and then immediately repeat: Mythos Preview was able to reason about a given assumption, why it was wrong, and what to change. In third-party evaluation, false claims of success, verification failures, and other behavioral issues related to rigor and honesty occurred at a significantly lower rate than Claude Opus 4.6 on the same tasks. |
4 | Mistakes can be more difficult to catch by humans. However, a tradeoff is that the model’s mistakes can be subtler and take longer to verify. It will occasionally expand scope beyond what was asked or make a change that does not preserve existing behavior in a way that is not obvious. Several engineers described the bottleneck shifting from the model to their ability to verify its work and steer agents. Its communication style can increase the difficulty of understanding its work. Mythos Preview sometimes defaults to a dense, terse style of writing that assumes the reader shares its context, and notes it leaves in code or pull requests tend to reference details a reader would not have. We found that this communication behavior was steerable with prompting. |
4 | Full autonomy is difficult in a production environment. From a reliability engineering perspective, the model still cannot be left alone in a production environment to use generic mitigations. It frequently mistakes correlation with causation, and it is not able to course-correct for different hypotheses. When asked to write incident retrospectives, more often than not it focuses on a single root cause and does not consider multiple contributing factors. |
4 | Can provide increased assistance to engineers in production environments. However, we have found this model to be a step change in two areas. The first is signal gathering and initial analysis, where, by the time an engineer has opened two dashboards, the model has already found the outliers and what’s breaking. The second case is navigating ambiguity when there is a clearly defined outcome. |
Vastly improved cybersecurity capabilities point to improved SWE capabilities in general.
Anthropic has decided not to release the model publicly, largely due to concerns around the sharp increase in the model’s capability to exploit security vulnerabilities in software. Mythos displayed a huge increase in its ability to exploit vulnerabilities, according to Anthropic. The company believed that public access to its models will aid attackers more than defenders in the short term and chose to provide initial access to select partners instead of a public release. We view the developments as another indication of improved software engineering capabilities in general.
Step-change in capability—outlier or a new trend?
Anthropic believes that the Mythos model represents an acceleration in model capability improvement. The sustenance of an accelerated capability improvement trajectory with continued focus on software engineering and broader IT services without sufficient offset from AI for business use case opportunities could drive further revenue deflation risks for Indian IT beyond our estimate of 3-3.5% annual growth impact in the next three years.
The key aspect to consider is the drivers behind increased capabilities that have not been disclosed by Anthropic. We expect Mythos to be larger and more costly to train than its predecessors. We note that no reliable estimates are available. If the model capability increase is largely driven by higher compute, sustaining the accelerated increase in capability could risk becoming cost prohibitive in the short term.